Buffer
什么是Buffer? 先通过一个粟子来看下:
const fs = require('fs')
fs.readFile('./txt.txt', function (err, body) {
console.log(body)
})
// <Buffer 48 65 6c 6c 6f 20 57 6f 72 6c 64 21>
上面粟子返回的就一个 Buffer, 可以看到 Buffer 类似于整数数组, 内部的数据是 16 进制
Buffer的作用?
JavaScript 语言自身只有字符串数据类型,没有二进制数据类型。但在处理像 TCP 流或文件流时,必须使用到二进制数据。因此在 Node.js中,定义了一个 Buffer 类,该类用来创建一个专门存放二进制数据的缓存区。简单来说 Buffer 就是帮助我们处理二进制数据的
注意 Buffer 的大小是固定的、且在 V8 堆外分配物理内存。 Buffer 的大小在被创建时确定,且无法调整
在 Node.js 中,Buffer 类是随 Node 内核一起发布的核心库。Buffer 库为 Node.js 带来了一种存储原始数据的方法,可以让 Node.js 处理二进制数据,每当需要在 Node.js 中处理I/O操作中移动的数据时,就有可能使用 Buffer 库。原始数据存储在 Buffer 类的实例中。一个 Buffer 类似于一个整数数组,但它对应于 V8 堆内存之外的一块原始内存。 Buffer 的大小在被创建时确定且无法调整,也就是说 Buffer 的大小是固定的
Buffer 的基本使用
// 创建一个长度为 10、且用 0 填充的 Buffer。
const buf1 = Buffer.alloc(10);
// 创建一个长度为 10、且用 0x1 填充的 Buffer。
const buf2 = Buffer.alloc(10, 1);
// 创建一个长度为 10、且未初始化的 Buffer。
// 这个方法比调用 Buffer.alloc() 更快,
// 但返回的 Buffer 实例可能包含旧数据,
// 因此需要使用 fill() 或 write() 重写。
const buf3 = Buffer.allocUnsafe(10);
// 创建一个包含 [0x1, 0x2, 0x3] 的 Buffer。
const buf4 = Buffer.from([1, 2, 3]);
// 创建一个包含 UTF-8 字节 [0x74, 0xc3, 0xa9, 0x73, 0x74] 的 Buffer。
const buf5 = Buffer.from('tést');
// 创建一个包含 Latin-1 字节 [0x74, 0xe9, 0x73, 0x74] 的 Buffer。
const buf6 = Buffer.from('tést', 'latin1');
为什么 Buffer.allocUnsafe() 和 Buffer.allocUnsafeSlow() 不安全
当调用 Buffer.allocUnsafe() 和 Buffer.allocUnsafeSlow() 时,被分配的内存段是未初始化的(没有用 0 填充)。 虽然这样的设计使得内存的分配非常快,但已分配的内存段可能包含潜在的敏感旧数据。 使用通过 Buffer.allocUnsafe() 创建的没有被完全重写内存的 Buffer ,在 Buffer内存可读的情况下,可能泄露它的旧数据。
Buffer 与字符编码
Buffer 实例一般用于表示编码字符的序列,比如 UTF-8 、 UCS2 、 Base64 、或十六进制编码的数据。 通过使用显式的字符编码,就可以在 Buffer 实例与普通的 JavaScript 字符串之间进行相互转换
const buf = Buffer.from('州','utf-8'); // <Buffer e5 b7 9e>
console.log(buf.toString('ascii')); // 'e7\u001e'
console.log(buf.toString('base64')); // '5bee'
console.log(buf.toString('utf-8')); // 州
Node.js 目前支持的字符编码包括:
ascii - 仅支持 7 位 ASCII 数据。如果设置去掉高位的话,这种编码是非常快的
utf8 - 多字节编码的 Unicode 字符。许多网页和其他文档格式都使用 UTF-8
base64 - Base64 编码。当从字符串创建 Buffer 时,按照 RFC4648 第 5 章的规定,这种编码也将正确地接受 “URL 与文件名安全字母表”
hex - 将每个字节编码为两个十六进制字符
utf16le - 2 或 4 个字节,小字节序编码的 Unicode 字符。支持代理对(U+10000 至 U+10FFFF)
ucs2 - 'utf16le' 的别名。
latin1 - 一种把 Buffer 编码成一字节编码的字符串的方式(由 IANA 定义在 RFC1345 第 63 页,用作 Latin-1 补充块与 C0/C1 控制码)
binary - 'latin1' 的别名。
Buffer的应用场景有哪些?
流
流是数据的集合(与数据、字符串类似),但是流的数据不能一次性获取到,数据也不会全部 load 到内存中,因此流非常适合大数据处理以及断断续续返回 chunk 的外部源。流的生产者与消费者之间的速度通常是不一致的,因此需要 buffer 来暂存一些数据。buffer 大小通过 highWaterMark 参数指定,默认情况下是 16Kb
存储需要占用大量内存的数据
Buffer 对象占用的内存空间是不计算在 Node.js 进程内存空间限制上的,所以可以用来存储大对象,但是对象的大小还是有限制的。一般情况下32位系统大约是1G,64位系统大约是2G
ascii、unicode 和 utf8
ascii
在计算机内部,字节是最小的单位,一字节为 8 位,每一位可能的值为 0 或 1。标准 ASCII 码使用指定的 7 位二进制数来表示 128 种可能的字符,这些字符包括大写和小写字母,数字 0 到 9、标点符号, 以及在美式英语中使用的特殊控制字符。后 128 个称为扩展 ASCII 码,它允许将每个字符的第 8 位用于确定附加的 128 个特殊符号字符、外来语字母和图形符号
unicode
全世界那么多语言文字,仅使用 ascii 编码肯定远远不够,为了能表示全世界了各种各样的语言文字,Unicode因此诞生,Unicode(UCS-Unicode Character Set) 也是一种字符编码方法,不过它是由国际组织设计,可以容纳全世界所有语言文字的编码方案,比如 U+0639 表示阿拉伯字母 Ain, U+0041 表示英语的大写字母 A ,U+4E25 表示汉字严。具体的符号对应表,可以查询 unicode.org,或者专门的汉字对应表。
unicode的问题
Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字严的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题
如何才能区别 Unicode 和 ASCII ?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢
英文字母只用一个字节表示就够了,如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是 0 ,这对于存储来说是极大的浪费
UTF-8
UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式,UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度
UTF-8 的编码规则很简单,只有二条:
对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
对于 n 字节的符号(n > 1),第一个字节的前 n 位都设为 1 ,第 n + 1 位设为 0 ,后面字节的前两位一律设为 10 。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母 x 表示可用编码的位。
| Unicode符号范围(十六进制) | UTF-8编码方式(二进制) |
|---|---|
| 0000 0000-0000 007F | 0xxxxxxx |
| 0000 0080-0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
下面,还是以汉字严为例,演示如何实现 UTF-8 编码。
严的 Unicode 是4E25(100111000100101),根据上表,严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是 11100100 10111000 10100101,转换成十六进制就是E4B8A5
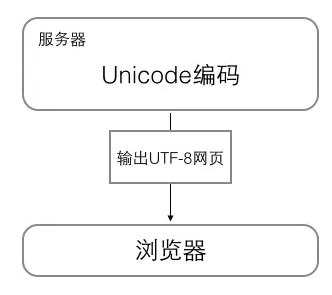
计算机中通用的字符编码的工作方式
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器: